Lecture 20: Verifiable MPC
Review from last lecture
In the first half of this course, we designed blockchains and broadcast protocols that provide strong integrity and availability. They are decentralized protocols that allow for outsourcing or federating data among a large number \(n\) of parties (e.g., servers on the Internet).
Fundamentally, blockchains and broadcasts achieve decentralization based on the principle of replication. The idea is that if you want information to live for a long time (either on the Internet or between a set of Byzantine generals), then you should store it in many computers or many people’s minds.
Replication is a powerful technique. But on its own, it seems incompatible with confidentiality. After all, if you give your data to \(n\) servers, how can you protect your data aginst them?
In this unit of the course, we began to study the concept of secure multi-party computation, or MPC.
MPC is a powerful tool that allows you to distribute your data among \(n\) parties, without giving your data to any single one of them! If a threshold number \(t\) parties meet then they can jointly reconstruct the data, but any coalition of smaller size cannot read your data.
MPC is based on the idea of randomness, rather than replication. The idea is to give each party a share of your secret: a random number, but chosen so that all of the shares jointly can be used to reconstruct your data.
![]()

We have seen two examples of secure multi-party computation so far.
In Lecture 4, we saw how a group of \(n\) people can produce a threshold Schnorr signature indicating that \(t\) of the \(n\) people approve the message.
In the last lecture, we showed that it is possible for \(n\) parties to collectively perform secure addition.
\(a\) 
|
\(b\) 
|
\(c\) 
|
\(a + b + c\) 
|
||
|---|---|---|---|---|---|

|
\(a_1\) | \(b_1\) | \(c_1\) | \(a_1 + b_1 + c_1\) | |

|
\(a_2\) | \(b_2\) | \(c_2\) | \(a_2 + b_2 + c_2\) |
Today, we will extend MPC in three ways.
We will securely compute any mathematical function \(f\) over secret shares of the data, and then only reconstruct the final result while keeping confidential all inputs and intermediate variables.
We will add integrity: that is, we will provide security against an actively malicious adversary Mallory, rather than a passive Eve.
We will add availability: that is, we will make sure that all computing parties have shares of the data, and they know that everyone else has shares too.
MPC of linear functions
The ideas that we have already shown for secure addition easily extend to cover all linear functions!
For instance, suppose that rather than calculating \(a + b + c\), we actually wanted to compute \(2a + 3b - c + 10\).
Since we are using additive secret sharing, and scalar multiplication also commutes over addition, each party can just compute its share of the result.
|
\(a\)
|
\(b\)
|
\(c\)
|
\(2a + 3b - c + 10\)
|
||
|---|---|---|---|---|---|
|
|
\(a_1\) | \(b_1\) | \(c_1\) | \(2a_1 + 3b_1 - c_1 + 10\) | |
|
|
\(a_2\) | \(b_2\) | \(c_2\) | \(2a_2 + 3b_2 - c_2 + 0\) |
Secure multiplication
Next, let’s try to multiply two secrets. Suppose that two data holders input \(a\) and \(b\), respectively. Can we somehow calculate secret shares of the product \(c = a \cdot b\)?
|
\(a\)
|
\(b\)
|
\(c = a \cdot b\)
|
||
|---|---|---|---|---|
|
|
\(a_1\) | \(b_1\) | \(\color{red}{??}\) | |
|
|
\(a_2\) | \(b_2\) | \(\color{red}{??}\) |
This is not as easy to compute. This time we cannot rely solely on commutativity of addition; we need to consider the distributive law as well.
Recall the relationships between the secret variables and their additive shares (all equations will be mod \(2^\ell\), but from now on I’m going to omit writing the modulus for brevity): \[\begin{align*} a &= a_1 + a_2 \\ b &= b_1 + b_2. \end{align*}\]
Hence, we want to compute: \[\begin{align*} c &= a \cdot b \\ &= (a_1 + a_2) (b_1 + b_2) \\ &= a_1 b_1 + a_1 b_2 + a_2 b_1 + a_2 b_2. \end{align*}\]
BU knows how to compute the term \(a_1 b_1\) on its own, and the Council knows how to compute \(a_2 b_2\) on its own. But it’s unclear how to compute the cross-terms \(a_1 b_2\) and \(a_2 b_1\) – that is, it’s unclear how to calculate these terms without the computing parties sending their shares to each other, but that would break data confidentiality.
I’ll show you today one way to resolve this problem. It relies on two useful insights.
Insight #1: let’s add a third computing server.
|
\(a\)
|
\(b\)
|
\(c = a \cdot b\)
|
||
|---|---|---|---|---|
|
|
\(a_1\) | \(b_1\) | \(\color{red}{??}\) | |
|
|
\(a_2\) | \(b_2\) | \(\color{red}{??}\) | |

|
\(a_3\) | \(b_3\) | \(\color{red}{??}\) |
At first glance, this might look to make the calculation even harder to perform. Now the distributive law says that we must calculate:
\[\begin{align*} c &= (a_1 + a_2 + a_3) (b_1 + b_2 + b_3) \\ &= a_1 b_1 + a_1 b_2 + a_1 b_3 \\ &\quad + a_2 b_1 + a_2 b_2 + a_2 b_3 \\ &\quad + a_3 b_1 + a_3 b_2 + a_3 b_3. \\ \end{align*}\]
Insight #2: Let’s give each computing party two of the three shares. This is called replicated secret sharing.
- This is still not enough information for each individual computing party to reconstruct any secrets.
- But now a threshold of \(t = 2\) of the \(n = 3\) parties will collectively have enough information to reconstruct secrets.
|
\(a\)
|
\(b\)
|
\(c = a \cdot b\)
|
||
|---|---|---|---|---|
|
|
\(a_1, a_2\) | \(b_1, b_2\) | \(c_1 = a_1b_1 + a_1b_2 + a_2b_1\) | |
|
|
\(a_2, a_3\) | \(b_2, b_3\) | \(c_2 = a_2b_2 + a_2b_3 + a_3b_2\) | |
|
|
\(a_3, a_1\) | \(b_3, b_1\) | \(c_3 = a_3b_3 + a_3b_1 + a_1b_3\) |
The punchline here is that: now there exists a computing server that can calculate each of the 9 terms in this product! So the three computing servers can calculate \(a \cdot b\) by working together in such a way that nobody has learned either \(a\) or \(b\).
\[\begin{align*} c &= (a_1 + a_2 + a_3) (b_1 + b_2 + b_3) \\ &= \color{red}{a_1 b_1} + \color{red}{a_1 b_2} + \color{gray}{a_1 b_3} \\ &\quad + \; \color{red}{a_2 b_1} + \color{blue}{a_2 b_2} + \color{blue}{a_2 b_3} \\ &\quad + \; \color{gray}{a_3 b_1} + \color{blue}{a_3 b_2} + \color{gray}{a_3 b_3}. \\ \end{align*}\]
There’s just one downside here: the computing parties have two shares of \(a\) and \(b\), but only one share of \(c\). So we cannot continue and multiply \(c\) times some other secret.
This is easy to fix with some communication: each computing party gives its share to one other party.
- \(P_1\) sends \(c_1\) to \(P_3\).
- \(P_2\) sends \(c_2\) to \(P_1\).
- \(P_3\) sends \(c_3\) to \(P_2\).
Now our invariant is maintained: each computing party starts with 2 out of 3 shares of each input, and completes multiplication with 2 out of 3 shares of each output.
To summarize, we have constructed a secure multiplication scheme with:
- One round of network communication between the computing parties.
- Correctness, since the \(n = 3\) parties work together to calculate all 9 terms shown by the distribute property.
- Perfect privacy, since each party has only 2 of the 3 additive shares of each secret.
- A threshold of \(t = 2\) parties that can reconstruct the answer (because they collectively hold all 3 shares).
MPC of everything
So far, we have seen one way to perform secure multi-party computation of \(+\) and \(\times\).
Importantly: \(+\) and \(\times\) are a Turing-complete set of gates! That is, we can write any data analytic as a circuit with \(+\) and \(\times\) gates. (This may not be the fastest way to compute \(f\), but it will always work in principle.)
For instance, given the circuit below along with secret shares of \(s\), \(t\), and \(x\) it is possible for the 3 computing parties to work together to calculate:
- secret shares of the intermediate value \(w\)
- secret shares of the final result \(y\)
and then reconstruct only the output \(y\).

Hence, the protocol we have constructed today can do a secure computation of any function, as long as:
- There is an honest majority of 2 honest servers out of 3.
- The one adversarial server is run by a passive eavesdropper Eve (i.e., it still follows the protocol).
It turns out that you can also perform MPC in the dishonest majority setting, and against an actively-malicious adversary Mallory.
20.2 MPC against Mallory
Recall from last time that our current protocol is only secure against a passive eavesdropper Eve. That’s because a malicious computing party Mallory can tamper with the result by adding some number to her own share.
|
\(a\)
|
\(b\)
|
\(c = a \cdot b \color{red}{+ 10}\)
|
||
|---|---|---|---|---|
|
|
\(a_1, a_2\) | \(b_1, b_2\) | \(c_1 = a_1b_1 + a_1b_2 + a_2b_1 \color{red}{+ 10}\) | |
|
|
\(a_2, a_3\) | \(b_2, b_3\) | \(c_2 = a_2b_2 + a_2b_3 + a_3b_2\) | |
|
|
\(a_3, a_1\) | \(b_3, b_1\) | \(c_3 = a_3b_3 + a_3b_1 + a_1b_3\) |
Here is one way to stop Mallory: we can add a fourth computing party for redundancy.
- Using replicated secret sharing, we can build a secure computation protocol with \(n = 4\) parties and a threshold of \(t = 2\) parties required to reconstruct.
- The data holders send 3 of 4 additive shares to each computing party.
|
\(a\)
|
\(b\)
|
\(c = a \cdot b\)
|
||
|---|---|---|---|---|
|
|
\(a_1, a_2, a_3\) | \(b_1, b_2, b_3\) | \(c_1\) | |
|
|
\(a_2, a_3, a_4\) | \(b_2, b_3, b_4\) | \(c_2\) | |
|
|
\(a_3, a_4, a_1\) | \(b_3, b_4, b_1\) | \(c_3\) | |

|
\(a_4, a_1, a_2\) | \(b_4, b_1, b_2\) | \(c_4\) |
The math for multiplication has gotten a bit more complicated, so I won’t write out explicitly how the shares of \(c\) are calculated.
\[\begin{align*} c &= (a_1 + a_2 + a_3 + a_4) (b_1 + b_2 + b_3 + b_4) \\ &= a_1 b_1 + a_1 b_2 + a_1 b_3 + a_1 b_4 \\ &\quad + \; a_2 b_1 + a_2 b_2 + a_2 b_3 + a_2 b_4 \\ &\quad + \; a_3 b_1 + a_3 b_2 + a_3 b_3 + a_3 b_4 \\ &\quad + \; a_4 b_1 + a_4 b_2 + a_4 b_3 + a_4 b_4 \end{align*}\]
Fortunately, the punchline is simple:
- For each of the 16 terms, there are two parties who know how to compute it!
- So for any computation that Mallory performs, there is an honest party who can check her math and call her out if she cheats.
Let’s take a step back and admire what we have done so far.
- We have been able to design MPC protocols to compute any data science computation.
- We can protect data confidentiality and integrity against a malicious Mallory.
The problem
In other words, this problem is very similar to the Byzantine generals question. You are a leader and you’re providing information to many other parties.

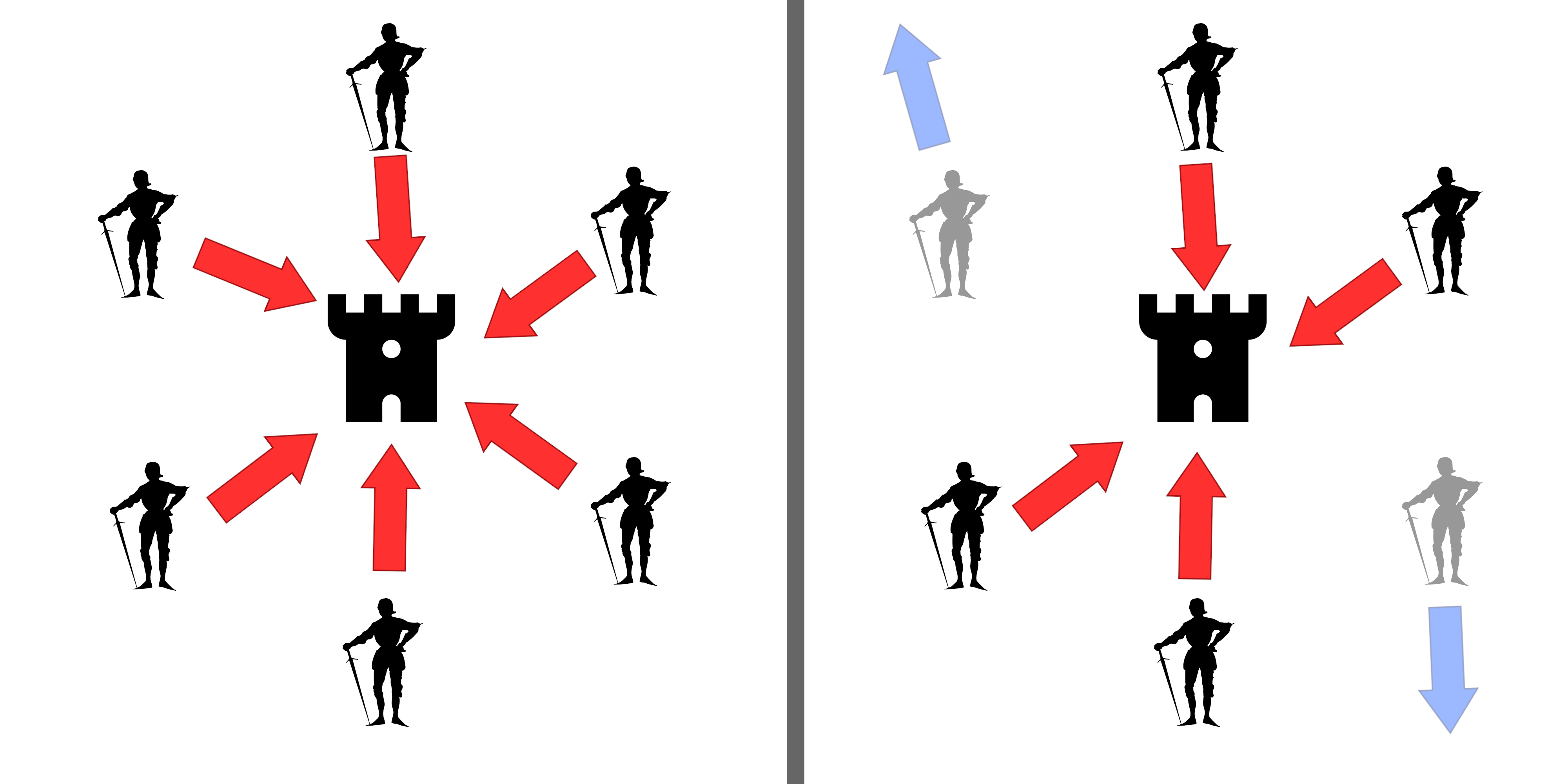{kind=link}
The main differences here are that:
- We are adding confidentiality through secret sharing, and
- There are two stages to the protocol: a dispersal stage and a retrieval stage.
But the other trust questions from the Byzantine generals problem remain. You don’t necessarily trust the other parties entirely, and they don’t entirely trust you either.
Question. How can we provide each party with a verifiability guarantee? That is:
- During dispersal, the cloud providers want to be convinced that they’re holding onto a share of a real secret that you will pay them for.
- During retrieval, you want to be convinced that the shares are correct (even though you have forgotten the secret yourself). Otherwise, you want to be able to pinpoint which provider(s) are sending you bad shares.
A construction
One way to solve this problem is to use Merkle trees. Recall that Merkle trees allow for uploading many files to the cloud, so that the cloud can prove that each file is part of the overall collection.


Concretely, here is a protocol that you can follow to disperse the shares and later retrieve the message.
In dispersal:
- The leader creates all secret shares such that \(x = \sum x_i\), and builds a Merkle tree of all shares \(x_i\). Let’s call the Merkle root \(h\).
- The leader sends each cloud provider its share \(x_i\), the Merkle root \(h\), and a proof \(\pi_i\) that connects its own share to the root \(h\). (The provider can check for itself that the proof \(\pi_i\) is correct, for the provided share \(x_i\) and Merkle root \(h\).)
- The leader saves the (small) Merkle root \(h\) and deletes the rest of its state. (After all, the purpose of cloud outsourcing is so that you don’t have to keep the secret \(x\) yourself.)
In retrieval:
- Each cloud provider sends their share \(x_i\) and proof \(\pi_i\) to the leader.
- The leader verifies each proof, and pays the corresponding provider if it’s correct. Alternatively, if a provider has cheated, the leader detects the error and takes appropriate action (e.g., sue the cloud provider in court, or take money that the provider has placed in escrow in a smart contract, etc).
Question. There is actually a bug in this protocol. Can you find it?
One problem is that the leader might use different Merkle tree roots \(h\) with each cloud provider. So even if the provider is honest, if the leader is malicious then they could send one cloud provider the wrong root \(h^*\) and later accuse the provider of cheating during the retrieval phase.
We can fix this problem using techniques from earlier parts of this course! Here are two recourses:
- Have the leader post the Merkle root \(h\) to a blockchain so that all providers can see them and know that they have a valid share \(x_i\) and proof \(\pi_i\) that connect to the publicly-posted \(h\).
- Have the leader run a Byzantine Broadcast protocol to disperse \(h\). Broadcast ensures that each provider receives \(h\), and that they are convinced that everyone else receives \(h\) too. (This approach is cheaper, but would not convince an outside party like a judge in a later court case.)
So here is one way to fix the protocol.
In dispersal:
- The leader creates all secret shares such that \(x = \sum x_i\), and builds a Merkle tree of all shares \(x_i\). Let’s call the Merkle root \(h\).
- The leader and providers conduct a Byzantine Broadcast to disperse the Merkle root \(h\) to all parties.
- Then, the leader sends each cloud provider its share \(x_i\) and a proof \(\pi_i\) that connects its own share to the broadcasted Merkle root \(h\). The provider refuses to participate further if the proof is incorrect.
- The leader deletes all state.
Retrieval can work the same as before. And in fact, the leader doesn’t even need to store the Merkle root \(h\) because it can just request it from all providers later: if there is an honest majority or a PKI, then the leader can distinguish the correct \(h\) from an incorrect one sent by a faulty cloud provider.
20.4 Commitment schemes from discrete log
A Merkle tree is a special case of a kind of cryptographic primitive that we discussed at the beginning of the semester: a commitment scheme. Recall that commitments are a digital analog to putting a written message inside of an envelope and placing it on the table.
- After Alice
commits to a message, then everyone knows that the message is inside of the envelope, but - Nobody can read the message until the envelope is
opened. (This is related to, but not the same thing as, encryption of a message.)
Commitments have two security guarantees.
- Binding: even against a malicious committer, it is infeasible for the committer to show a different message \(m^*\) in the
openstep than the message \(m\) that it originally used during thecommitroutine.
| Mallory | Bob | |
|---|---|---|

|
\(\quad \overset{c}{\longrightarrow} \quad\) |

|
- Hiding: even against a malicious receiver, from only the commitment \(c\) it is infeasible to learn anything about the message \(m\).
| Alice | Mallory | |
|---|---|---|

|
\(\overset{c}{\longrightarrow}\) |
|